RAG 最早有 Facebook 2020年提出
单纯的生成问题为: $y = f(x)$ 由输入序列通过生成器得到输出序列
RAG: $y=f(x,z)=f(x,g(x))$ 额外补充了相关信息用于生成 $g$ 为 retrieval function
现在看 RAG 主要分为三个部分
- retrieval : 建立索引和完成检索 (再包括输入处理之类的前处理)
- generation : 基于内容的生成
- denoising: 多信源信息提取
- reasoning: 多信源合成推理
- workflow/integration : 整体数据流控制
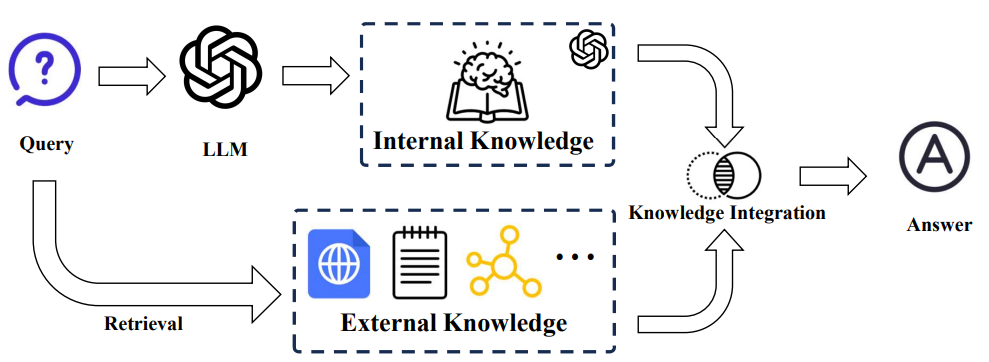
基础流程:
- 理解用户意图 (文本建模/指令重写/语义分析)
- 知识检索 (倒排索引/近似最近邻)
- 知识集成
- 内容生成
- [内容评估]
- 上下文相关性 (ARES/RAGAS/TruLens: Context Relevance) (KILT: Recall@k )
- 答案连贯性 (CRUD/RECALL/ARES/RAGAS) recall/precision/faithfulness/…
- 答案准确率
- 知识引用与溯源 (LongBench-Cite/LQAC) 引用准确率 溯源得分
Retrieval
用户意图理解
Query Decomposition 用于强化推理能力
- least-to-most prompting: 将复杂问题分解为多个子问题
- Self-ask: 通过让模型提出并回答后续问题来进一步完善推理过程 实现更好的多跳推理
- Chain-of-Verification: 通过让模型独立进行事实核查来验证其响应 从而提高答案的可靠性
- Search-in-the-Chain: 将信息检索(IR)集成到推理过程中 (模型构建一个查询链 其中每个查询都通过 IR 进行验证)
Query rewrite
- Rewrite-Retrieve-Read: 利用 LLM 在检索之前创建和完善查询 (使用强化学习指导可训练的重写器 以优化查询与目标知识之间的对齐)
- BEQUE: 专注于电子商务搜索中的长尾查询 通过监督微调、离线反馈和对比学习来弥合语义差距 显著改善了业务指标
- HyDE (Hypothetical Document Embedding): 引入了一种**零样本(zero-shot)**的密集检索方法 (使用遵循指令的 LLM 生成一个假设文档 然后对该假设文档进行编码 并用于检索相关文档)
- Step-Back Prompting: 鼓励 LLM 从具体示例中抽象出高层概念 从而改善其在 STEM、多跳问答和基于知识的推理等任务中的推理能力
知识来源与解析
解析不同类型数据
- 结构化知识 (KG/Tables)
- 半结构化知识 (HTML)
- 非结构化 (PDF & others)
- 多模态数据
知识嵌入
将数据变为向量形式
分块 Chunk Partitioning (难点在于分块后保留意义并且尽可能减少冗余和信息丢失)
传统分块
- 固定长度+overlap: 基于固定长度分块 然后块间有overlap
- 基于规则
- 基于语义
智能策略
- proposition level
- LLM 动态划分 (LumberChunker)
- late chunking: 划分之前嵌入整个文档
文本嵌入模型 Text Embedding Models
早期方法缺乏全面的语义表示
- BoW: 只关注词频 会忽视语法
- N-gram: 只捕获语言结构 但是维度变大有问题
- TF-IDF: 关注词频和上下文 但是受到高维限制
- word2vec/GloVe/fastText 是静态的
所以主流使用BERT系列和现在更新的Decoder-only embedding model
- BGE
- NV-Embed
- SFR-Embedding
- Qwen-Embedding
- …
另外还有一些领域模型
- WE-iMKVec: 用于healthcare
- USTORY: 用于新闻领域
知识索引
索引是 RAG 中数据结构化的组织方式 用于高效访问和检索信息
- 结构化索引: 基于预定义属性组织数据 (REALM 使用文本倒排索引)
- 非结构化索引: 向量索引/图索引
- 混合索引: 使用结构化索引快速筛选 再使用向量索引
索引更新与存储
增量更新
周期性重建 (更新模型)
Chroma使用分布式架构 可以水平扩展Faiss为内存数据库Weaviate使用图结构优化向量存储和查询
知识检索
基于查询从向量数据库中识别和提取相关知识的过程
根据相似性函数分类的三种检索策略
- 稀疏检索(spare retrieval): 使用稀疏向量进行匹配分析 BM25/TF-IDF/uniCOIL/SPLADE 后两者是根据Transformer编码到高维
- 密集检索(Dense retrieval): 将查询和文档编码到低维向量空间中 通过点积或余弦相似度衡量相关性
- 混合检索(Hybrid retrieval)
搜索方法主要是两种
- 最近邻搜索(NNS)
- Brute Force
- KD/Ball/M tree
- 近似最近邻搜索(ANNS)
- Locality-sensitive/Spectral/Deep Hashing
- K-means tree
- HNSW 分层可导航小世界图 (Chroma用的这个)
知识集成
将检索到的外部知识与生成模型的内部知识无缝对齐
- 输入层
- text-level: (重排后) 直接拼接
- feature-level: 以向量形式拼接
- 中间层: 在中间层通过模块作为额外信息给到模型
- 输出层: 结合logits (kNN-LM/kNN-MT/EDITSUM)
Generation
生成分为两个部分
- Denoising: 减轻检索到的无关内容 矛盾或误导性信息影响
- Reasoning: 综合多文档信息 建立逻辑连贯性
Denoising
Explicit Denoising Techniques: InstructRAG使用rationale generation 生成文档间逻辑链来验证关联性
Discriminator-Based Denoising: 通过判别器评估和筛选
Self-Reflective and Adaptive Denoising: Self-RAG 通过反思来迭代过滤
Contextual Filtering and Confidence Scoring
Reasoning
Structured Knowledge and Graph-Based Reasoning
Cross-Attention for Multi-Document Reasoning: RETRO使用分块注意力来关注检索信息
Memory-Augmented Reasoning: 使用记忆模块来保持细节抑制性
Hierarchical and Multi-Pass Reasoning
Citation
引用生成策略:
- 同步引用生成: 响应生成的同时实时检索信息和引用 (WebGPT/GopherCite/RECLAIM)
- 后生成引用检索: 先有答案 后检索引用 (PARR/LaMDA)
引用粒度发展
- 粗粒度: 早期模型引用整个文档或URL
- 细粒度: RECLAIM 链接到句子 Longcite提出Coarse to Fine流水线 生成句子级引用
Workflow
RAG training
RAG = Retriever X Generator
- 静态训练: 固定一个 训练一个
- 单向训练: 基于一个优化另一个
- 协同训练: 同时训练两个
Agentic RAG
核心进行了扭转 RAG 成了工具的一部分
- 查询理解&策略规划
- 工具使用
- 推理&决策优化
Practice
Conclusion
 Mindmap of “A Survey on Knowledge-Oriented Retrieval-Augmented Generation” (arXiv:2503.10677)
Mindmap of “A Survey on Knowledge-Oriented Retrieval-Augmented Generation” (arXiv:2503.10677)