并行技术
- DP: Data Parallel (切分数据)
- TP: Tensor Parallel (按矩阵切分模型 竖着切) 通信代价大 都在node内部
- PP: Pipeline Parallel (分层切分模型 横着切)
- SP: Sequence Parallel
- EP: Expert Parallel (For MoE)
- HP: Hybrid Parallel
进程通讯
- peer-to-peer: sender-receiver 一对一通信
- collective: 一组进程完成通信
主要有三类
发送: 全量发送(broadcast) / 拆分发送(scatter)
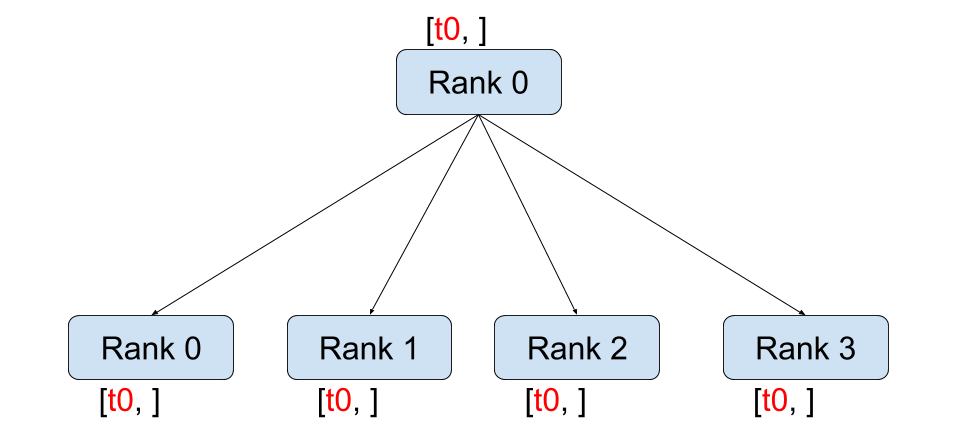
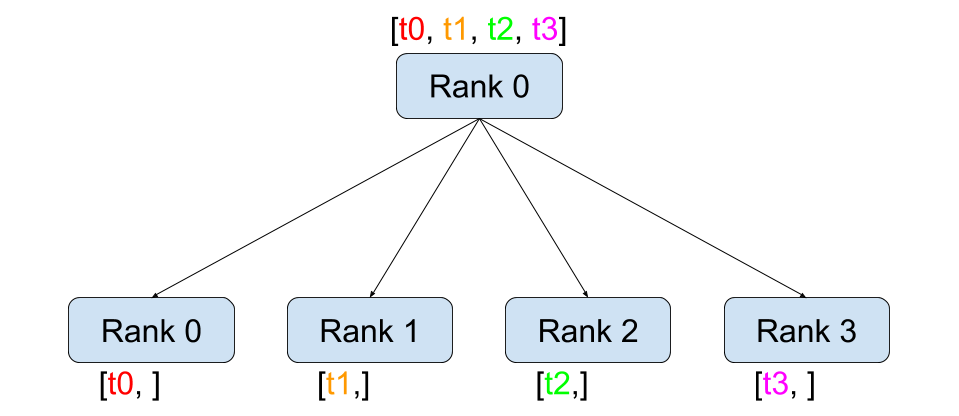
接收: 接收合并(gather) / 接收求和(reduce)
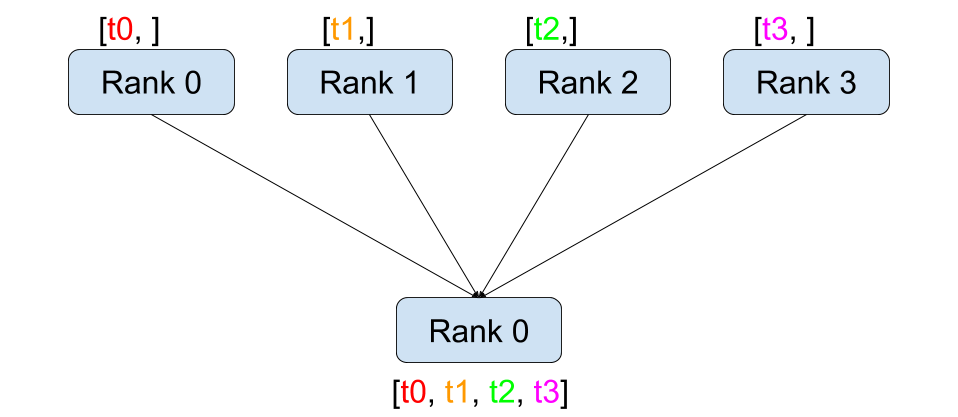
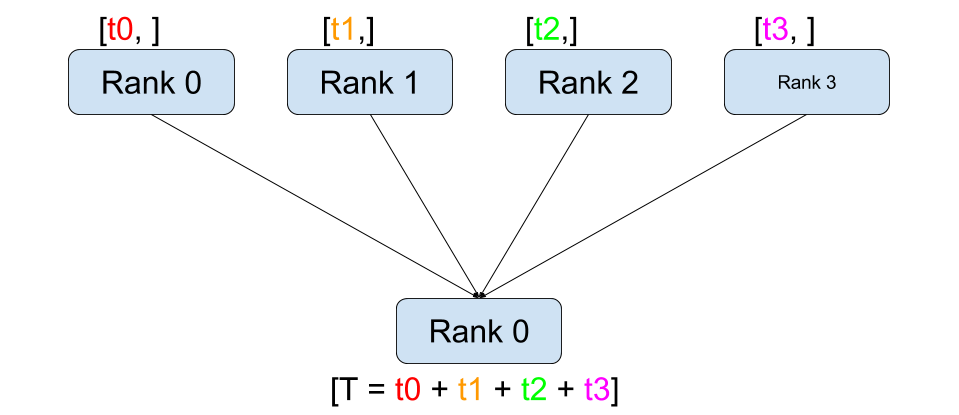
全操作: 接收合并(all-gather) / 接收求和(all-reduce)
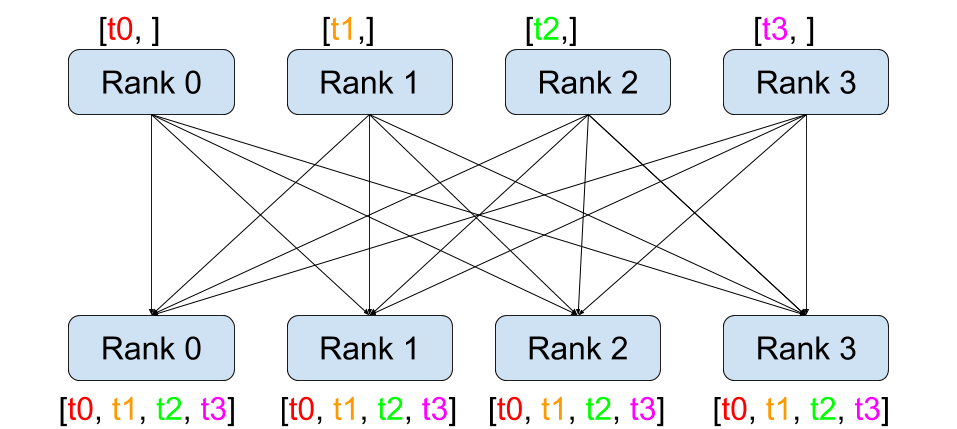
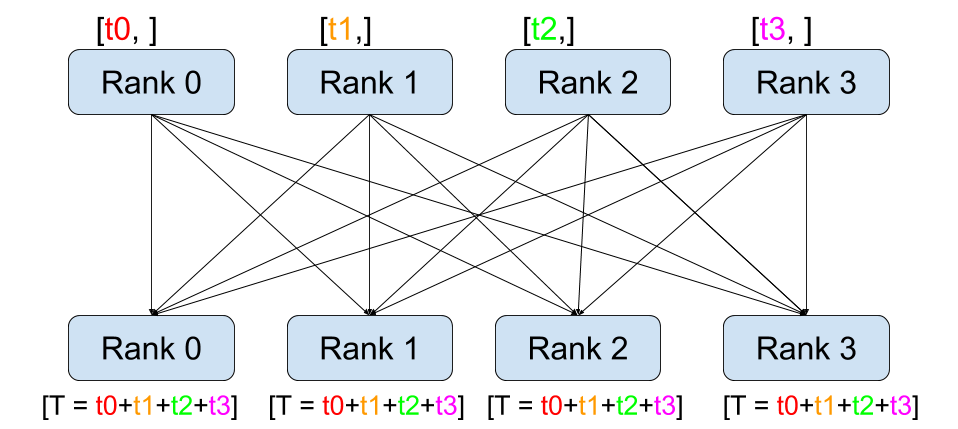
scatter - gather 是逆操作
all-gather/reduce 相当于 gather/reduce + broadcast
并行技术
DP
- 拷贝模型
- 分割数据
- All Reduce梯度然后更新
数据并行的数据流
- CPU拷贝到GPU
- GPU计算得到梯度
- reduce结果到参数服务器(CPU or GPU0)计算总的梯度
- 参数服务器broadcast到其他GPU
PyTorch DDP 基于多进程实现 每个进程有独立优化器 进程间只传递梯度
- GPU0 broadcast
- send data to GPUs
- AllReduce gradient
TP
将一个张量沿特定维度分成若干块 (通信代价大 一般node内使用)
只处理
linear不处理其他层
考虑到矩阵乘法(下面是列并行 还可以行并行 1D shard)
- 列并行:
- 拆分 linear
- 计算后 all-gather
- 行并行:
- 拆分 linear
- scatter 输入
- 计算后 all-reduce
$$ [C_1, C_2] = C = A\times B = A \times [B_1,B_2] $$
于是可以把计算拆分到多个设备上 计算完成之后再all-gather
Megatron-LM
Transformer块主要有Attn和MLP组成 这俩都可以切分
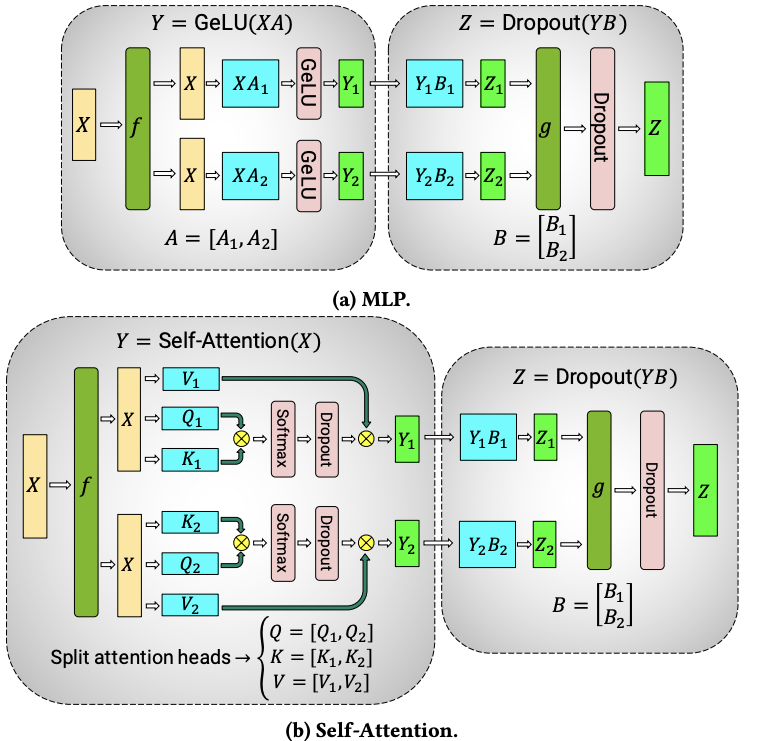
f 和 g 是共轭函数
f在前向传播是恒等算子 反向传播是 all-reduceg在前向传播是all-reduce 反向传播是恒等算子
需要保证head和MLP隐藏层纬度是device整数倍
PP
按层分割成若干块
前向传递激活 后向回传梯度 (容易产生大量气泡)
- 朴素流水并行即把多层拆分后放在多张卡上 等效于单卡扩大N倍显存
- microbatch流水并行通过拆分minibatch来增加流水线 提高GPU利用率
GPipe
GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism arXiv:1811.06965
- 提出microbatch降低bubble $O(\frac{K-1}{K+M-1})$ K是设备数 M是minibatch数量
- 通过重计算(re-materialization)降低显存消耗
PipeDream
PipeDream: Fast and Efficient Pipeline Parallel DNN Training arXiv:1806.03377
之前的流水线都是 F-then-B 即先前向算完microbatch再后向 会导致有很多中间变量和梯度的存储 显存利用率不高
1F1B 为前向计算minibatch和后向交叉进行 不需要等待microbatch计算结束的同步锁(pipeline flush)
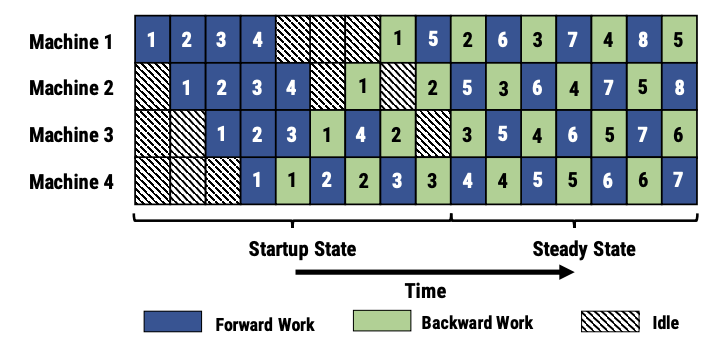
1F1B-RR 使用轮询调度模式将任务分配在同一个stage的各个设备 保证minibatch前向后向都在一台机器
…
ZeRO
模型在训练时不是显存大头 减少显存占用重点还在优化器和梯度
常见优化器数据量(基于模型参数量的倍数)
16bit 就是 2x 参数量
Optimizer Memory SGD 0 SGD w M 2 Adam 2+2 AdamW 2+2 Muon 2
ZeRO-1: 分片优化器 ZeRO-2: 分片优化器和梯度 ZeRO-3: 分片优化器和梯度和模型权重
FSDP 将AllReduce分解为Reduce-Scatter + AllGather
Reduce-Scatter 为基于rank进行求和
SP
Colossal
Sequence Parallelism: Long Sequence Training from System Perspective arXiv:2105.13120 解决模型输入长度限制
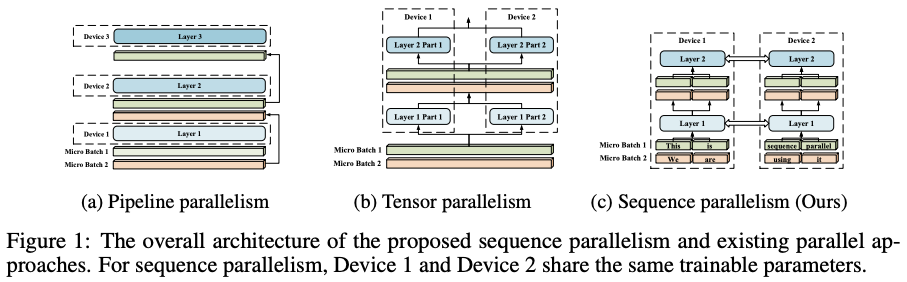
- 将输入序列分割成多个块 并将每个块输入到其相应的设备中
- 结合环状通信与自注意力计算 并提出了环自注意力
Megatron-LM
Reducing Activation Recomputation in Large Transformer Models arXiv:2205.05198 为了降低显存 跟上面的关系不大
将 Transformer 层中的 LayerNorm 以及 Dropout 的输入按输入长度(Sequence Length)维度进行了切分 使得各个设备上面只需要做一部分的 Dropout 和 LayerNorm 即可
EP
MoE的基础架构修改是把Linear改成了Gated Linears 就显得EP类似TP特例
$$ \text{MoE}(x) = \sum_{i=1}^nG(x)_iE_i(x) $$
$$ G(x) = \text{TopK}(softmax(W_g(x)+\epsilon)) $$
GShard
Encoder-Decoder 的FFN变成交错的FFN/MoE Top-2 gating
使用 Auxiliary loss 尽量均分token
Switch-Transformer
T5 + MoE 在 C4数据集上预训练
简化Routing 每次top1
GLaM
E64A2 (Expert 64 Active 2)
Google 打过 GPT-3 的模型
ref: