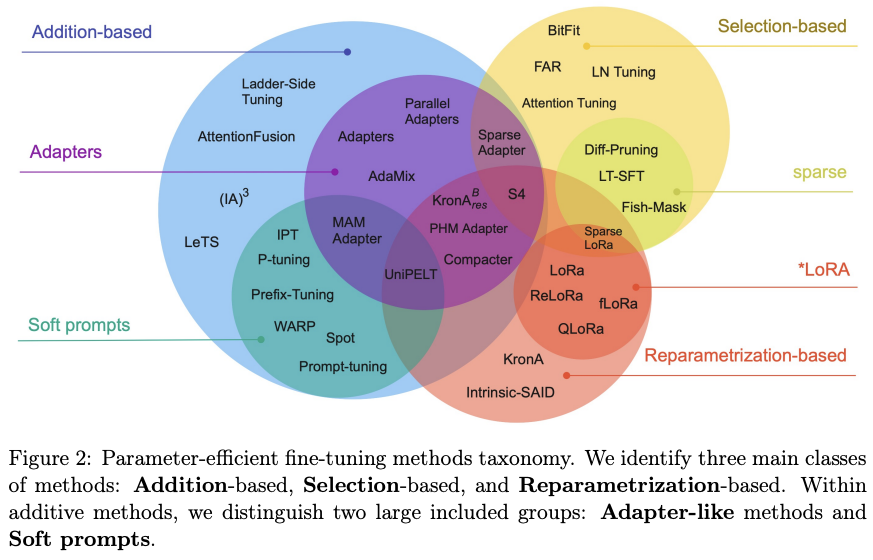
主为分为三大类
- 增加额外参数 (Addition)
- 选取一部分参数更新 (Selection)
- 引入重参数化 (Reparametrization)
Addition
Adapter
Parameter-Efficient Transfer Learning for NLP arXiv:1902.00751
在 MHA 和 MLP 后面各添加一个 adapter
训练 adapter 和 layer norm
adapter 结构为 带skip-connection的MLP 隐变量降维 $h \leftarrow h + f(hW_{\text{down}})W_{\text{up}}$
AdapterFusion
AdapterFusion:Non-Destructive Task Composition for Transfer Learning arXiv:2005.00247
解决多任务微调问题
- Adapter 训练: 微调下游任务 (仅在MLP后添加)
- Adapter 聚合: 引入新的AdapterFusion模块来组合多个Adapter信息 (结构为(Cross) Attention)
AdapterDrop
AdapterDrop: On the Efficiency of Adapters in Transformers arXiv:2010.11918
缓解 Adapter 导致的推理延迟问题
(Adapter) 从每层一个 Adapter 的标准架构 删除前面 Tranformer 层的 Adapter (AdapterFusion) 对每层的 Adapter 进行剪枝
Prefix Tuning
Prefix-Tuning: Optimizing Continuous Prompts for Generation arXiv:2101.00190 一种soft prompt
为模型输入构造可学习 Prefix 用于标识不同任务 (新的 task token/embedding)
(从past_key_values添加)
- Decoder: 输入前添加
- Encoder-Decoder: 两端输入前都添加
Prefix 前面加 MLP 结构 训练完只保留 Prefix
设置每层都加 MLP 做 Prefix
Prompt Tuning
The Power of Scale for Parameter-Efficient Prompt Tuning arXiv:2104.08691
差不多就是 Prefix Tuning 不加 MLP 的版本 (训练任务embedding 然后加入输入)
提出 Prompt Ensembling 再一个Batch里面混合多个任务数据 (就是用T5-XXL训练类似T5的任务)
P-Tuning
GPT Understands, Too arXiv:2103.10385
只修改输入层
使用 Prompt Encoder (LSTM+MLP) 编码 virtual embedding (task related prompt)
P-Tuning V2
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks arXiv:2110.07602
P-Tuning 的主要问题
- 缺乏模型参数规模和任务的通用性
- 缺少深度提示优化
每层都加入 Prompt Embedding (相当于Prefix Tuning + P-Tuning)
Selection
BitFit
BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models arXiv:2106.10199
只更新(部分)bias参数
发现 query 和 MLP up_proj 的 bias 变化最大
Reparametrization
LoRA
LoRA: Low-Rank Adaptation of Large Language Models arXiv:2106.09685
在 QKVO 加俩小矩阵 $\text{BA}\in \mathbb{R}^{d\times d}, \text{A}=\mathcal{N}(0, \sigma^2)\in \mathbb{R}^{d\times r}, \text{B}=0\in\mathbb{R}^{r\times d}$
$W = W^{(0)}+ \Delta = W^{(0)}+BA$
实验发现(QKVO) 矩阵加在 QV 上效果最好
Thinking Machines 发现 MLP 上的 LoRA 效果更好 具体发现如下:
- 对于中小型指令和推理数据(instruction & reasoning) LoRA 与 FullFT 相同
- 超出 LoRA 容量数据集 表现较差 训练效率下降
- 对大批量容忍度更低 正常训练也需要更高的学习率(10x)
- LoRA 用于 MLP/MoE 效果好于 attn
- LoRA 在强化学习上的表现与 FullFT 相当 (强化学习所需容量非常低)
AdaLoRA
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning arXiv:2303.10512
动态更新不同模块LoRA的r
$W = W^{(0)}+ \Delta = W^{(0)}+U\Sigma V^\top$
做奇异值分解和重要性评分来做
QLoRA
QLoRA: Efficient Finetuning of Quantized LLMs arXiv:2305.14314
使用4bit量化模型 使用bf16计算 (计算前 反量化4bit参数)
- 4bit NormalFloat: 正态分布权重的新数据类型
- 双量化: 连续两次量化
- 分页优化器: CPU/GPU之间换页 (optim offload)
Fusion
MAM Adapter
Towards a Unified View of Parameter-Efficient Transfer Learning arXiv:2110.04366
Mix-And-Match Adapter
融合 Adapter Prefix-Tuning LoRA
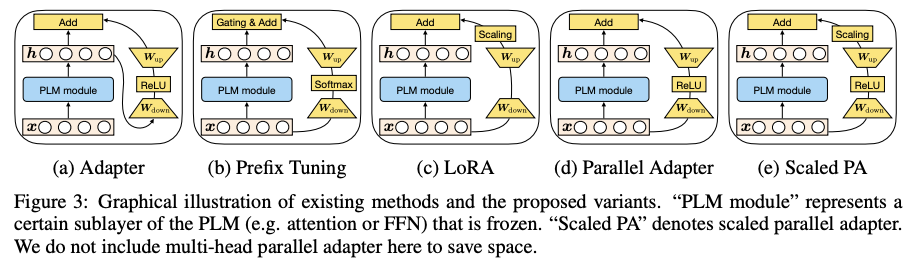
有如下结论:
- 并行adapter优于串行adapter
- FFN并行的adapter优于MHA并行的adapter
- soft prompt 可以小参数更新提高注意力
所以 MAM adapter == FFN 并行 adapter + soft prompt
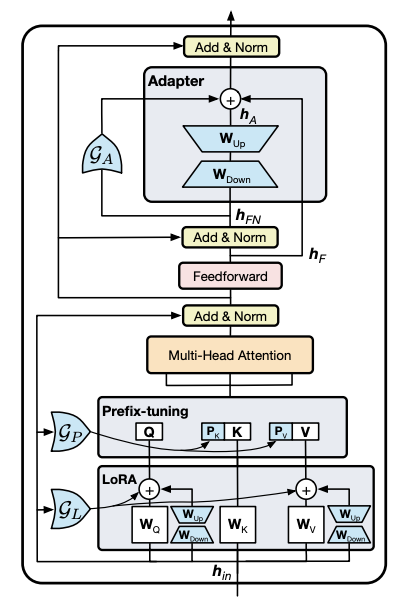
UniPELT
UNIPELT: A Unified Framework for Parameter-Efficient Language Model Tuning arXiv:2110.07577
PELT: Parameter-Efficient Language model Tuning
使用门控的adapter LoRA Prefix-Tuning 混合方案
ref: