引言
Flamingo的挑战
- 结合多个单模态预训练模型
- 冻结LM的自注意力层 并在其之间添加交叉注意力
- 特殊门控机制
- 支持图片和视频
- Transformer模型 特别是最近LM 会因为简单将高维视觉数据添加到序列中而受到内存限制
- 使用基于感知机(Perceiver-based)架构可以从图片和视频中抽取少许定量的visual token(~100)
- 使用异构数据获取通用能力
- 爬的网页数据
- 用标准配对的图文和视频文本数据集结合出新的数据集来解决图文弱关联的问题
新的贡献
- 可以接受图文混排的并且输出文本的新架构
- 保留起始模型优点 训练多模态模型 (70B Chinchila -> 80B Flamingo)
- 可使用不同尺寸的视觉输入
model
连接视觉模型和语言模型
- 多模态BERT模型: 使用预训练目标检测器来获取视觉信息(visual region proposal -> visual word)
- VideoBERT使用k-means将视频帧编码为视觉词
- Masked Region Modeling(MRM)用于掩码视觉词
- 需要下游任务微调
- 对比双编码器(contrastive dual encoder)
- 大量基于对比学习的vision-language模型
- 使用独立编码器分别编码视觉信息和文本输入 使用对比损失将向量嵌入联合空间
- (预训练任务: 匹配视觉信息和文本描述)
- 能够学习到高度泛化的视觉表示
- 在zero-shot视觉文本检索和分类上表现很好
- 只能用于封闭域问题(close-ended tasks)
- 视觉语言模型
- 接近于Flamingo以自回归方式生成文本
- 最早应用为提取视觉描述(image2text)
- VirTex: 将captioning作为前置任务来从文本描述学习到视觉表示
- CM3: 生成图片的HTML网页而不是单纯的描述信息
- concurrent works: 将大量的视觉任务规范化为文本生成任务
- 分类
- visual QA: 回答与图像相关问题
- visual entailment: 通过图像验证假设是否成立
- visual captioning: 为图像生成文字描述
- visual grounding: 将自然语言与图像中的对象进行匹配
- 物体检测
- VisualGPT: 用LLM的权重初始化VLM
- (冻结原有LLM)使用可训练的visual encoder 进行 prefix tuning/prompt tuning
- MAGMA: 添加bottleneck adapters到冻结的LM上
- ClipCap: vision-to-prefix transformer 去映射视觉特征到prefix上
- VC-GPT: 通过将新的学习层移植到冻结的语言模型来探索调整冻结的语言模型
- PICA: 使用现有的VLM和GPT3语言描述来交流图片内容
Flamingo
- 冻结预训练大模型
- 在vision encoder与冻结模型间使用transformer结构的mapper
- 训练与冻结语言模型层交错的交叉注意层
dataset
LM
现有的一些其他模型数据来源
- 抓取带有alt文本的图片和带有描述的视频
- 使用带字幕的视频
- 整个多模态的网页
Flamingo: 只获取网页的自然语言文本来简化基础LM的文本生成任务
few-shot in vision
few-shot learning
- 基于分析查询(query)和示例(support examples)的相似性
- 基于使用梯度更新的优化 旨在找到一个良好的模型初始化 非常适合于适应
- 使用示例直接微调模型(use support examples to directly generate model weights adapted to the novel task)
- “in-context” few-shot prompts 从只是用于LM的文本变成了图文
Flamingo: 使用in-context学习范式同时是第一个in-context few-shot video learning model
方法
- 一个预训练的LM(ARLM)
- (Visual-Model)使用对比图文的方法(contrastive text-image approach)训练一个vision encoder (类似**CLIP**) 使用抽取语义空间特征 描述视觉属性
连接这两部分
- 冻结模型参数
- 在visual-encoder之后添加Perceiver Resampler(trainable)
- input: 空间特征(spatio-temporal features)
- output: 固定大小的visual tokens
- 在模型中添加交叉注意力层
- input: visual tokens and text tokens
- output: interleaved tokens
可以建模文本y与图片/视频x交错的似然
$$ p(y|x) = \prod^L_{l=1}p(y_l|y_{<\mathcal{l}}, x_{\le\mathcal{l}}) $$
- $y_l$ 是第l个language token
- $y_{<l}$ 表示前序的token
- $x_{\le l}$ 表示前序的visual token
模型架构
- LM: 70B Chinchilla
- VisionEncoder: Normalizer-Free ResNet(NFNet) F6
visual process
Vision encoder: pixels2features
使用图片对进行对比目标学习 (two-term contrastive loss)
对比相似度:
mean(pooling(image_encoder)) · mean(pooled(BERT))
最后输出为特征$X_f$的2D空间表格 然后被压缩为1D
处理视频: 1FPS抽帧 独立编码为顺序特征 拼接后送入下游组件
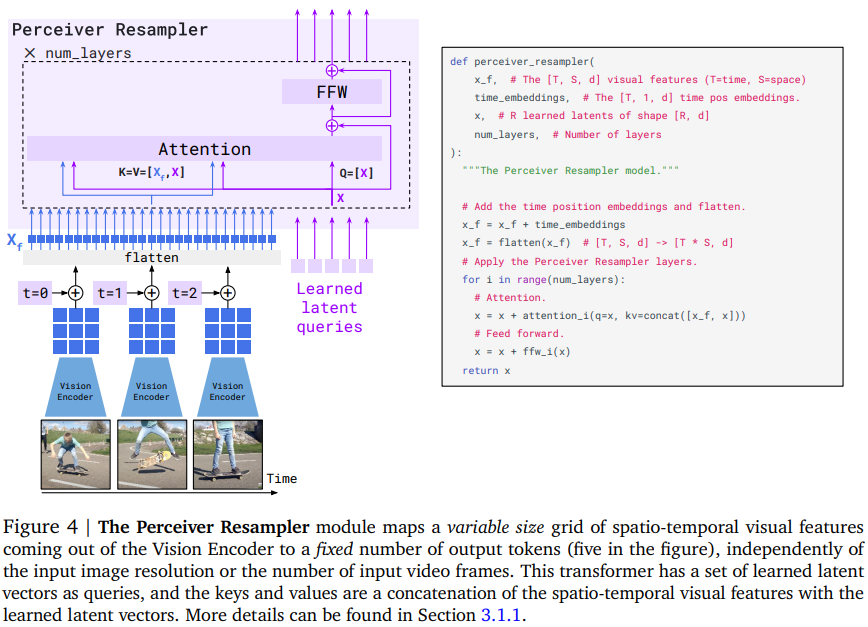
Perceiver Resampler: features2vtokens
连接vision encoder和冻结模型
- input: 不定长图片/视频特征
- output: 定长视觉输出
重采样到定长输出的目的是显著减少 图文交叉注意力层 的计算复杂度(在处理多个长视频的时候效果明显)
output token 的数量与 latent queries数量一致
在视觉表征上调节冻结模型
文本生成在Transformer decoder上完成
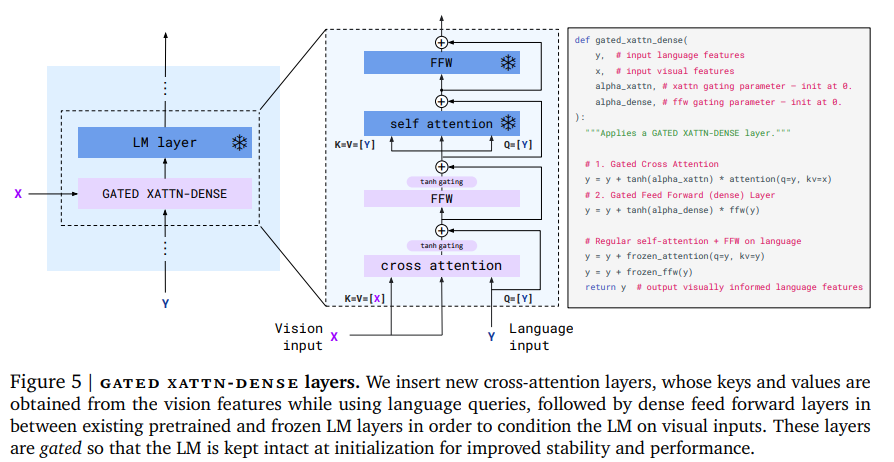
在冻结的模型中插入门控交叉注意力(gated xattn-dense)
类似GPT-2的风格 在QKV上应用了layer-norm
在训练中 模型逐渐平滑接入交叉注意力层 text-only model -> VLM
门控机制提升了训练的稳定性和最终的表现
可以控制xattn插入的比率来正规化模型表达内存消耗和时间复杂度
多种视觉输入支持

混排视觉数据和文本
- y:text sequence
- x:images/videos sequence
- positions of the visual data in the text
定义函数 $\phi:;[1, L] \to [0, N]$ 为每个文本位置分配该位置前最后一个图片/视频的索引(之前没有则为0)
多图片注意力
实际上在 门控交叉注意力 上实现了
Perceiver Resampler 限制了token中视觉成分的数量
让每个token与之前的一张图片计算交叉注意力
单图片交叉注意力的一个重要优点在于让模型无缝归纳任意数量的图片 而不会受限于训练数据
在Flamingo训练时 最多每条序列5张图片 但在验证时可以做至少32-shot的归纳
在混合数据集上训练
数据集的三类数据
- Image-Text pair
- Video-Text pair
- Multi-Modal Massive Web(M3W) 多图
只有无标签数据 没有包含任何下游任务相关的数据集
图文混排
从网页中提取文字和图片(~43M pages) 保留图片相对位置
将输入中的图片替换为<image> 并在<image>和<EOS>前添加<EOC>(end of chunk)
<EOC> 会被添加到LM词典中并且随机初始化和训练 还会在采样和推理时用于指示给定图片的文本预测的结束
对于每篇文档 抽取 L=256 token和 N=5 张图
output:
- images: [N=5, T=1, H=320, W=320, C=3]
- text: [L=256]
- indices: $\phi$ [L=256] 跟text形状一样
视觉信息与文本配对
数据集
- ALIGN 1.8B 图片和Alt文本
- LTIP(Long Text & Image Pairs) 312M images
- VTP(Video & Text Pairs) 27M短视频(~22s avg)
处理逻辑跟上面一样
output:
- images: [N=1, T, H=320, W=320, C=3] 图片T=1 视频T=8
- text: [L=32/64]
- indices: $\phi$ [L]
训练和优化策略
最小化负对数log似然
梯度累积
基于few-shot in-context learning的任务调整
In-context learning
使用in-context learning评估模型对于新任务快速调整的能力
以 (image, text) 或者 (video, text) 的形式提供样例+单个视觉查询 作为few-shot的prompt(默认乱序拼接样例)
Zero-shot 泛化
开放域问题不太行
封闭域问题还可以
基于检索的上下文示例选择
当给的示例太多时 泛化性能减弱 更倾向于在样例中选择
附录
- 数据集
- M3W
- LTIP
- VTP
- 模型卡
- 实验详细
- 对话prompt
数据集
- M3W收集: 跟MassiveWeb dataset类似
- 过滤:
- 非英语内容
- 使用Google SafeSearch过滤
- 扔掉没图的
- 删掉低质量文档和重复的
- 文本中关联性最强的图要么在本文前面要么在文本后面 采样是前后概率为 1/2
- 使用Google internal deduplication去重图片
- 视频不去重